

 相关专题:
相关专题:
唐忠林,许盛宏,谭志远
(中国电信股份有限公司广东研究院,广东 广州 510630)
【摘要】为了深入了解运营商的网络覆盖程度,提升网络资源投放效率,通过Mean-Shift算法对基站的MR数据做首次聚类分析,预测出局部最优的基站覆盖中心点,再用DBSCAN算法预测出全局最优的基站覆盖中心点。在此基础上分析三大运营商基站小区在地理位置上的部署密集程度,从而获得每个运营商的网络热点区域分布,为网络规划和智慧网优提供全方位的分析方法。
【关键词】MR Mean-Shift DBSCAN 聚类算法
doi:10.3969/j.issn.1006-1010.2017.22.001 中图分类号:TP312 文献标志码:A 文章编号:1006-1010(2017)22-0001-04
引用格式:唐忠林,许盛宏,谭志远. 基于大数据对运营商基站覆盖中心点的预测及对比分析[J]. 移动通信, 2017,41(22): 1-4.
1 引言
随着大数据时代的迅猛发展,人们对LBS(Location Based Services,基于位置服务)的需求也快速增长,无线定位技术逐步得到重视,位置服务已经成为一种热门的技术。辅助GPS(AGPS)定位技术结合了GPS定位和蜂窝基站定位的优势,借助蜂窝网络的数据传输功能,可以快速精准地定位,在移动设备尤其是手机终端中被广泛使用[1]。运营商通过更新4G网络主设备网管,即新增辅助GPS和异网检测功能,实现了基站MR(Measurement Report,测量报告)数据版本升级。在新的数据源中不仅能够获取到精确的GPS地理信息,同时异网检测功能也可以针对其他运营商网络覆盖强度进行周期测量,从而解决了当前MR应用过程中定位精度不足和只能评估本网络覆盖情况的局限[2]。通过本次研究,可以有效拓展MR的分析能力,针对三网(中国移动、中国电信、中国联通)的覆盖情况进行对比分析。
本文通过对辅助GPS数据的挖掘分析,预测出运营商的基站覆盖中心点,可以实现运营商之间的网络可持续化对比,为解决传统三网对比测试样本不充足、对比不全面的问题提供一种有效解决方案。
2 运营商基站覆盖中心点预测
以基站采集到的终端测量报告作为数据源,并将数据源按频点和PCI(Physical Cell Identifier,物理小区标识)进行分组,对分组后的每组数据用Mean-Shift(偏移均值向量算法)算法做首次密度聚类[3-4],找到局部最优的基站覆盖中心点。结合专业的业务背景知识,对局部基站覆盖中心点用DBSCAN算法做二次聚类,找到全局最优的基站覆盖中心点[5-8]。最后用本网的主覆盖小区来验证所预测出来的基站覆盖中心点的正确性。具体流程如图1所示:
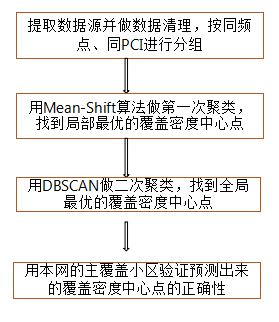
图1 运营商基站覆盖中心点预测流程
2.1 数据源提取及清洗
本模型采用中国电信全省MR的辅助GPS相关数据,主要包括:各运营商的频点、PCI、用户个人上报的百度经纬度、地市、中国电信主服务小区百度经纬度等属性,并对每条记录中的异常数据、无效数据进行了清洗。为减少邻区等干扰因素影响模型的准确度,本模型只提取了室外且相距主服务小区1 km以内的MR记录。
2.2 Mean-Shift算法聚类过程
Mean-Shift算法是一个迭代的过程。对于d维空间的N个样本点,首先随机选择一个点,并以这个点为圆心、以R为半径做一个d维的高维球,落在这个球内的所有样本点和圆心都会产生一个向量,每个向量都以圆心为起点、以球内的样本点为终点,计算出球内所有向量的和,最终得出Mean-Shift向量。再以Mean-Shift向量的终点为圆心重复上述步骤。由同起点向量求和法则可知,Mean-shift向量最终将收敛到概率密度最大的区域[9]。Mean-Shift向量的基本形式如下:
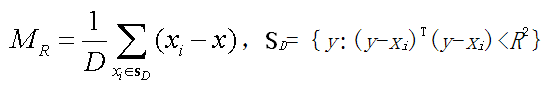 (1)
(1)
其中,x为空间中任意一点;D表示在N个样本点xi中有D个点落在SD区域中。
Mean-Shift算法的伪代码思想如下:
(1)随机选择一点为中心点,固定一个窗口,计算出Mean-Shift向量;
(2)判断是否达到收敛,若收敛则终止,否则执行第(3)步;
(3)以Mean-Shift向量的终点为新的中心,重复上述步骤[10]。
由于获取到的用户辅助GPS数据呈现出无规律分布,因此采用基于概率密度的Mean-Shift算法进行聚类分析。该算法忽略了数据源中的异常值,每次只对窗口内局部数据进行计算,计算完成后再移动窗口。
本模型首先以中国电信的数据做训练集,以频点和PCI作为分组条件,分别把具有相同频点和PCI的个人上报百度经纬度进行聚类。经过多次模型训练并结合业务实际,本模型最终设置的Mean-Shift窗宽系数为0.02,聚类得到多个同一频点和PCI下多个基站覆盖中心经纬度。预测中国电信室外的基站覆盖中心点有159 284个,将预测出来的覆盖中心点经纬度与中国电信MR数据本身提供的小区百度经纬度在百度地图上作距离对比。结果表明,对于广州市区统计出基站覆盖中心点有80.3%落在主覆盖小区对应方向角附近150 m以内,但在同一频点和PCI下有部分预测的基站覆盖中心点相距较近。结合专业的业务知识,运用区域聚类算法DBSCAN进行二次聚类,将属于同频点同PCI且相距较近的基站覆盖中心点聚为一个新中心点。
2.3 DBSCAN二次聚类过程
DBSCAN是一种基于高密度连通区域的聚类算法,能够将具有足够高密度的区域划分为簇。该算法需要两个核心的参数:一个参数是半径,表示以给定点P为中心的圆形邻域的范围;另一个参数是以点P为中心的邻域内最少点的数量[11]。
基于本模型需求和专业的业务知识,模型设置的半径为200 m,邻域内最少点数量设置为1,从而可以将具有相同频点和PCI且距离较近的基站覆盖中心点聚类成一个新的中心点。将基站覆盖中心点经纬度与中国电信MR数据提供的小区经纬度作距离核对,该模型预测出中国电信室外共有155 244个基站覆盖中心点。对于广州市区统计出基站覆盖中心点有83.6%落在主覆盖小区对应方向角附近150 m以内,符合实际业务规则。
DBSCAN算法的伪代码思想如下:
(1)选取邻域半径为200 m,邻域内最少点数为1;
(2)随机选取一点为中心点,计算相同频点和PCI下的主覆盖小区中心点的距离,若满足条件,则加入该邻域,并以新加入的点为中心判断其余点是否满足条件,直到遍历完所有点,计算出该邻域新的中心点,并把属于该邻域的点从原数据中删除;
(3)从剩余的点中随机选取一点为新的中心,重复第(2)步直到原数据中所有点都被重新归类完毕为止。
3 运营商基站覆盖中心点对比分析
通过上述模型,采用相同的方法可以预测出异网基站覆盖中心点的位置及其数量,预测出运营商A室外有231 948个基站覆盖中心点、运营商B室外有92 668个基站覆盖中心点。将三家运营商的基站覆盖中心点预测结果显示在百度地图上,以广州两个区域Ⅰ、Ⅱ为例,具体如图2和图3所示:
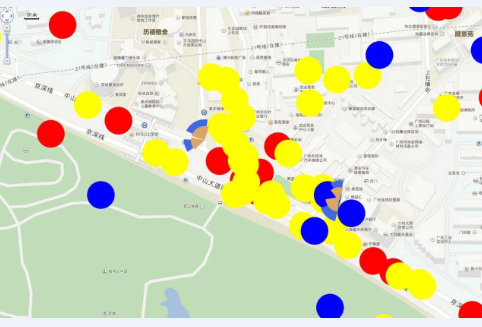
图2 区域Ⅰ运营商基站覆盖中心点对比
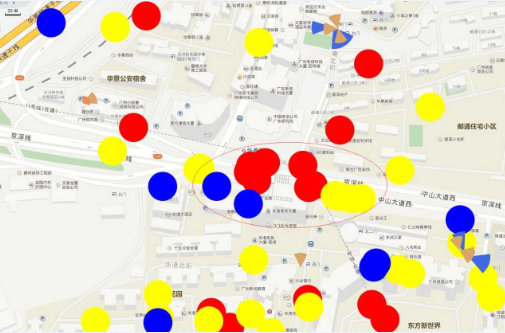
图3 区域Ⅱ运营商基站覆盖中心点对比
其中,扇形表示运营商真实的主覆盖小区所在的位置;圆形表示用模型预测出来的基站覆盖中心点所在的位置;黄色表示运营商A、蓝色表示运营商B、红色表示运营商C。
从图2和图3可以看出,预测得到的基站覆盖中心点跟真实的小区相距较近,能够直观地描绘出三家运营商的覆盖区域及覆盖密度。通过这种直观的比较,不仅可以掌握异网的大致网络分布,而且也易于了解哪些区域是本网盲区、哪些区域需要加强覆盖,为网络建设规划和智慧网优提供强有力的支撑。
4 结束语
本文通过对MR数据的挖掘分析,预测出运营商的基站覆盖中心点,可以全面掌握运营商主覆盖小区的大致分布和覆盖密度,为全面评估网络覆盖程度提供有力支撑,也为掌握异网的网络规划和发展规模提供理论依据。后续将对全集团的MR数据做相同的挖掘分析,为全集团的网络规划、智慧网优、优化布局提供全方位智能化分析方法,进一步提升网络资源投放效率。
参考文献:
[1] 左超,耿庆鹏,刘旭峰. 基于大数据的电信业务发展策略研究[J]. 邮电设计技术, 2013(10): 1-4.
[2] 顾芳,刘旭峰,左超. 大数据背景下运营商移动互联网发展策略研究[J]. 邮电设计技术, 2012(8): 21-24.
[3] Ester M, Kriegel H P, Sander J, et al. A density-based algorithm for discovering clusters in large spatial databases with noise[J]. Knowlegdge Discovety Data Mining, 1996: 226-231.
[4] 彭宁嵩,杨杰,刘志,等. Mean-Shift跟踪算法中核函数窗宽的自动选取[J]. 软件学报, 2005,16(9): 1542-1550.
[5] 何中胜,刘宗田,庄燕滨. 基于数据分区的并行DBSCAN算法[J]. 小型微型计算机系统, 2006,27(1): 114-116.
[6] 熊忠阳,孙思,张玉芳,等. 一种基于划分的不同参数值的DBSCAN算法[J]. 计算机工程与设计, 2005(9): 2319-2321.
[7] 荣秋生,颜君彪,郭国强. 基于DBSCAN聚类算法的研究与实现[J]. 计算机应用, 2004,24(4): 45-46.
[8] 王桂芝. 基于密度聚类分析的相关算法研究[J]. 电脑知识与技术, 2013(30): 6714-6716.
[9] D Comaniciu, P Meer. Mean shift: a robust approach toward feature space analysis[J]. Journal of Image and Signal Processing, 2002,24(5): 603-619.
[10] RT Collins. Mean-shift blob tracking through scale space[J]. Computer Vision and Pattern Recognition, 2003: 234.
[11] 韩利钊,钱雪忠,罗靖,等. 基于区域划分的DBSCAN多密度聚类算法[J/OL]. [2017-06-14]. http://www.arocmag.com/article/02-2018-06-047.html.★
作者简介
唐忠林:工程师,硕士毕业于华南理工大学,现任职于中国电信股份有限公司广东研究院,从事大数据挖掘、算法模型等工作。
许盛宏:工程师,学士毕业于重庆邮电学院,现任职于中国电信股份有限公司广东研究院,从事核心网研究及支撑工作。
谭志远:工程师,学士毕业于华南理工大学,现任职于中国电信股份有限公司广东研究院,从事大数据数据库、数据平台管理、云计算等技术研究及支撑工作。 
作者:唐忠林 许盛宏 谭志远 来源:《移动通信》





