

 相关专题:
相关专题:
0 前言
随着移动互联网时代的到来,在移动通信市场上,内部而言,各家运营商之间的产品优势相对有限;外部而言,运营商面临互联网企业的冲击,对单个用户价值的开发使得竞争更加激烈。在存量用户十分有限的情况下,对于运营商而言,维护高价值老客户的投入比开发新用户的投入更能有效节省企业成本开支。电信客户离网分析相关研究已经开展了很多年,从早期利用数据库进行OLAP分析,到使用数据挖掘算法进行用户离网预测。针对离网倾向的用户实施客户挽留,展开维系与关怀,以利于电信企业客户的保持,对增强电信企业的综合竞争力具有重要意义[5-6]。本文介绍了使用近年来机器学习中的流行算法来分析潜在离网用户的方法,和早期研究使用的逻辑回归、决策树[2]、SVM等方法相比,XGBOOST适用于二分类问题,并具有很好泛化能力。
1 数据挖掘流程
采用机器学习的方法进行数据挖掘,一般流程如图1所示。
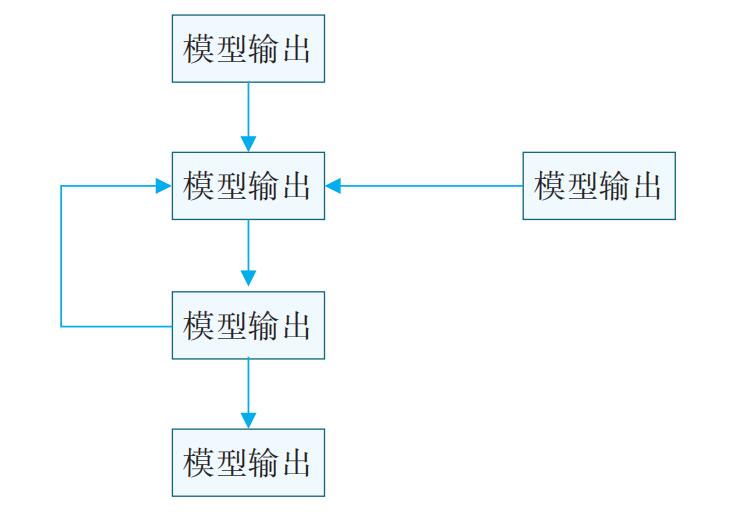
图1 数据挖掘基本流程
给机器学习算法输入的数据,是经过处理后的数据,包括对空值、异常值的处理,对数据取值范围和取值类型的处理,离散化、归一化处理等;使其满足所选择的机器学习算法对数据类型和数据值的要求。算法选择模块包含训练模型时的单个算法选择以及多个算法融合时的多算法选择,以实际开发时测试样本集的预测正确率为标准调整。各阶段耗费时间占比如图2所示。
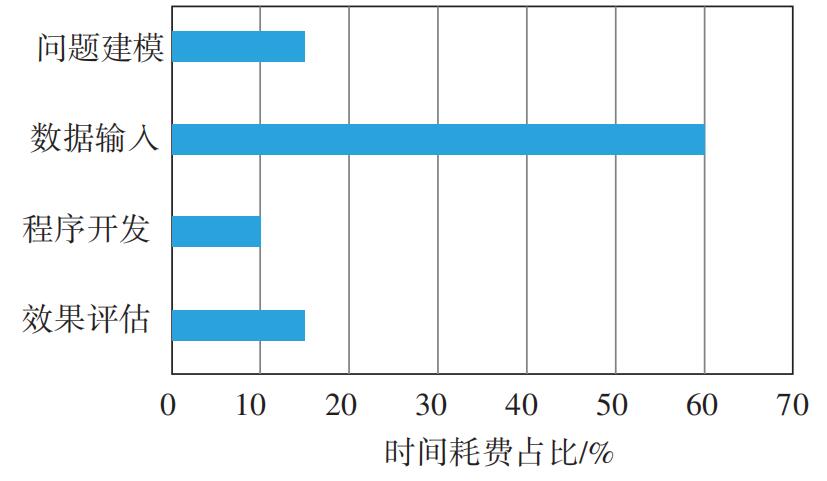
图2 数据挖掘项目时间耗费占比
其中程序开发涵盖算法选择、算法实现和模型输出。由于目前很多算法已经实现了功能模块化,因此,这部分算法可以通过直接调用现成API[3]或者安装功能模块来实现。
2 用户离网预测问题
在预测离网客户的分析中,通常有几个关键步骤:问题定义、算法选择、数据准备、结果评估、反馈修正。
问题定义:在电信企业实际业务中,对客户离网理解最深入的是该领域的专家,因此对客户流失的重要因素的判定具有指导意义。相关理解应包括,定义什么是离网,离网用户类型有哪些(高价值用户还是普通用户),离网有哪些形式(是主动流失,例如由于客户不满意当前服务或竞争对手提供了更优质服务而主动停止当前服务,进行转网、退网,还是被动流失,例如学生客户毕业异地工作,或客户职业升迁异地调动的原因),离网分析通常更关注高价值用户的主动流失,他们是电信企业利润的重要来源。
算法选择:确定好问题以后,对离网用户的分析是根据准备使用的算法来进行建模的,需要确定原始数据集的来源,以及使用潜在离网用户的哪些相关属性。同时,原始数据集通常也被拆分为2个部分,一部分是训练集,用作构造算法模型,另一部分是测试集,用于评估分类算法通过学习生成的模型是否合理。两者的拆分通常是按照1∶1的比例,也可以根据业务分析专家的判断进行比例的调整。
数据输入:据统计,电信企业平均每月有97.5%的在网客户,以及2.5%的离网客户,因此原始数据集存在严重的比例不平衡。另外,电信企业一个地(市)的用户数据就达到几十万甚至上百万,如果对所有数据进行训练,时间上很难满足要求。并且,原始数据集由于来源于电信企业的不同领域和部门,许多比较重要的属性值存在缺失和错误,降低了对潜在用户离网的预测精度。同时,要进行用户离网预测,需要将能收集到的用户相关属性组织成一张表,称为数据聚集,新生成的表称为数据宽表,例如将用户基本信息、持有终端信息和月消费信息整合为一张宽表。
效果评估:算法输出的模型用于测试样本集时,混淆矩阵约定:TP(True Positive)指真实为1,预测也为1;FN(False Negative)指真实为0,预测为1;FP(False Positive)指真实为1,预测为0;TN(True Negative)指真实为0,预测也为0,则模型效果可通过以下各项指标反映[4]。
准确率 P = TP/(TP+FP) (1)
召回率 R = TP/(TP+FN) (2)
F1-score = 2×P×R/(P+R) (3)
3个指标用于综合评估模型效果优劣。
模型输出:通过指标的综合评定,确定使用或保留何种机器学习算法,保存训练模型以供调用。
3 机器学习算法
机器学习从无序的数据中挖掘有用的信息,狭义的指计算机“学习算法”的一门学问。关键术语包括:特征(也称为属性)、标识(标签)、任务(分类或聚类、回归)、训练样本集、测试样本集等。开发机器学习应用程序的基本步骤通常包括[1]:收集数据、标准化输入数据、分析输入数据、训练模型、测试验证、实际应用。机器学习的目的就是给定输入x,得到预测值,并希望预测值与真实值y之间的误差尽可能的小。下面介绍机器学习的4个经典挖掘算法。
3.1 逻辑回归
相对于线性回归处理因变量是连续变量,逻辑回归能更好地适用于因变量是分类变量的回归问题,常见的就是二分类问题。逻辑回归的因变量和自变量之间通常采用Sigmoid函数来描述:
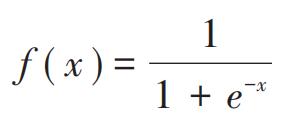 (4)
(4)
它是一个S形的曲线(见图3)。
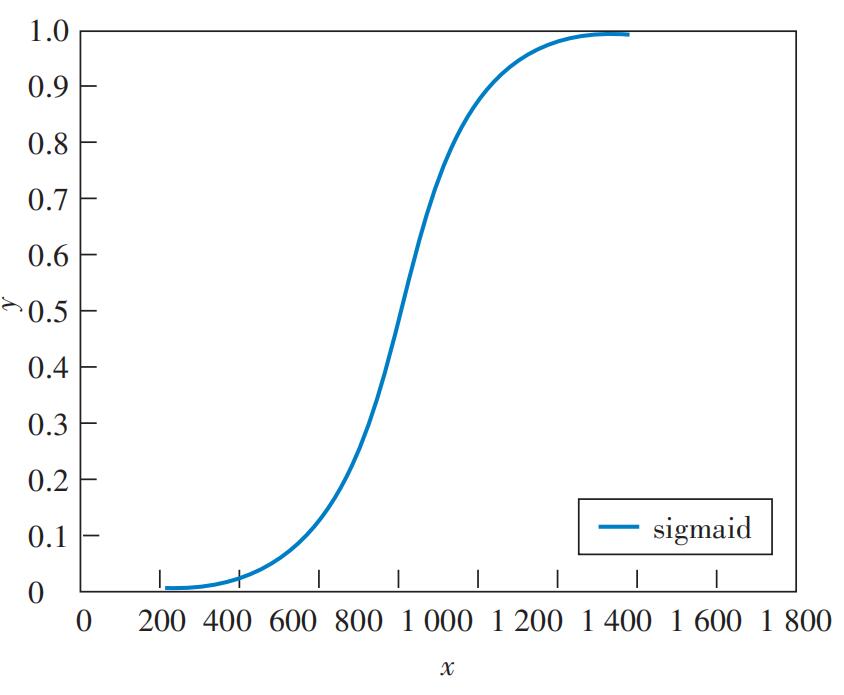
图3 S形函数
3.2 决策树
决策树是最经常使用的数据挖掘算法,大量地应用于分类问题。它是一种树形结构,分为内部节点,叶子节点和分支。每个内部节点表示一个特征或者属性上的测试,每个分支代表一个测试输出,每个叶子节点代表一个类别。它的优点是计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关的特征数据。图4为决策树经典模型图。
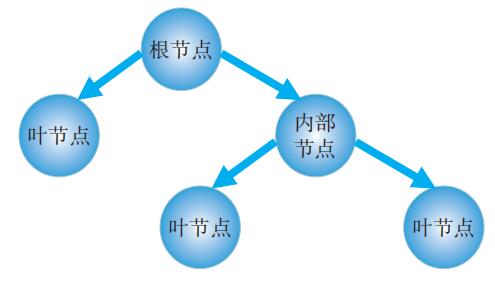
图4 决策树
3.3 支持向量机(SVM)分类算法与核函数
SVM是机器学习中的有监督线性分类算法,最初正式发表于1995年。SVM应用在文本分类尤其是针对二分类任务显示出卓越的性能,因此得到了广泛的研究和应用,后期在多分类任务也进行了专门推广。SVM通过向高维度空间映射来解决多维线性不可分问题,使样本线性可分。如图5所示,可将一维不可分问题转化为二维可分问题[7]。核函数选择是SVM中性能差别的最大原因。核函数选择不合适,意味着样本被映射到了不合适的特征空间,很可能导致性能不佳。

图5 SVM高维映射
3.4 XGBoost
XGBoost(eXtreme Gradient Boosting)采用了回归树和集成Boosting 2种技术。在数据建模中,当我们有数个连续值特征时,经常采用Boosting分类器将成百上千个分类准确率较低的树模型组合起来,形成一个准确率很高的预测模型。XGB可以理解为多个树的并行预测,并将预测分值相加用于类别判断。这个树模型经过不断地迭代,在每次迭代就生成一棵新的树,从而使预测值不断逼近真实值(即进一步最小化目标函数)。
XGBoost的并行树如图6所示,以样本1为例,预测得分为:Tree1.样本1.得分(2)+ Tree2.样本1.得分(0.9)=2.9,相比于样本2的-0.8,样本3的-0.1,样本4、5的-1.9,具有更大的预测概率。注意到,由于XGBoost出众的效率与较高的预测准确度在机器学习领域引起了广泛关注。
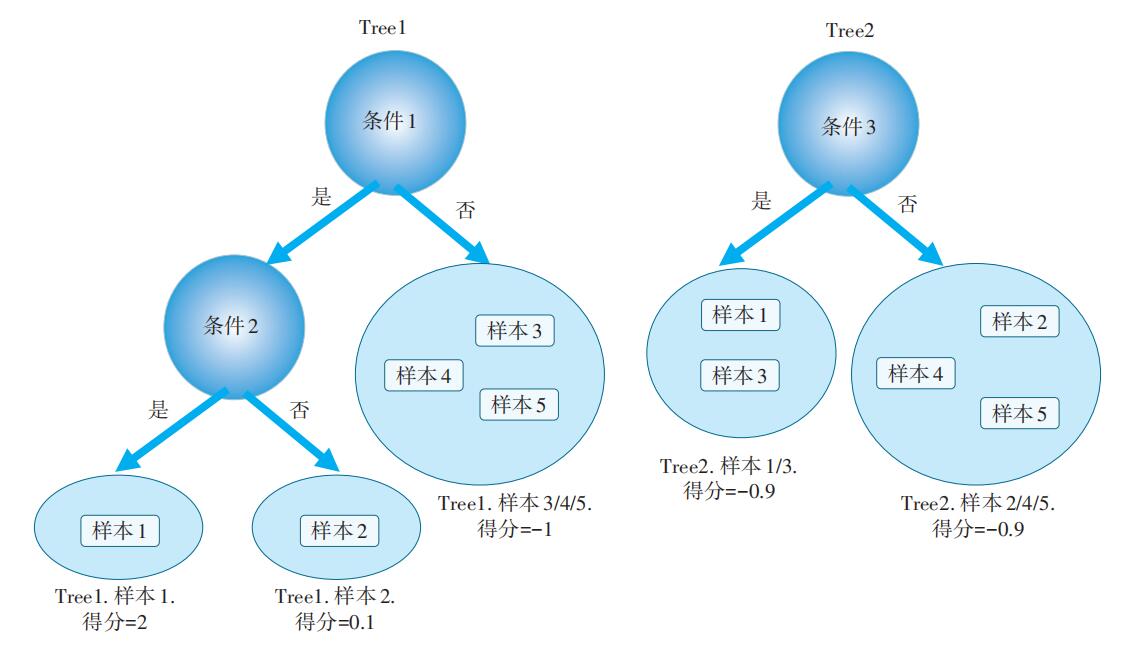
图6 XGBoost 并行树
4 实验验证
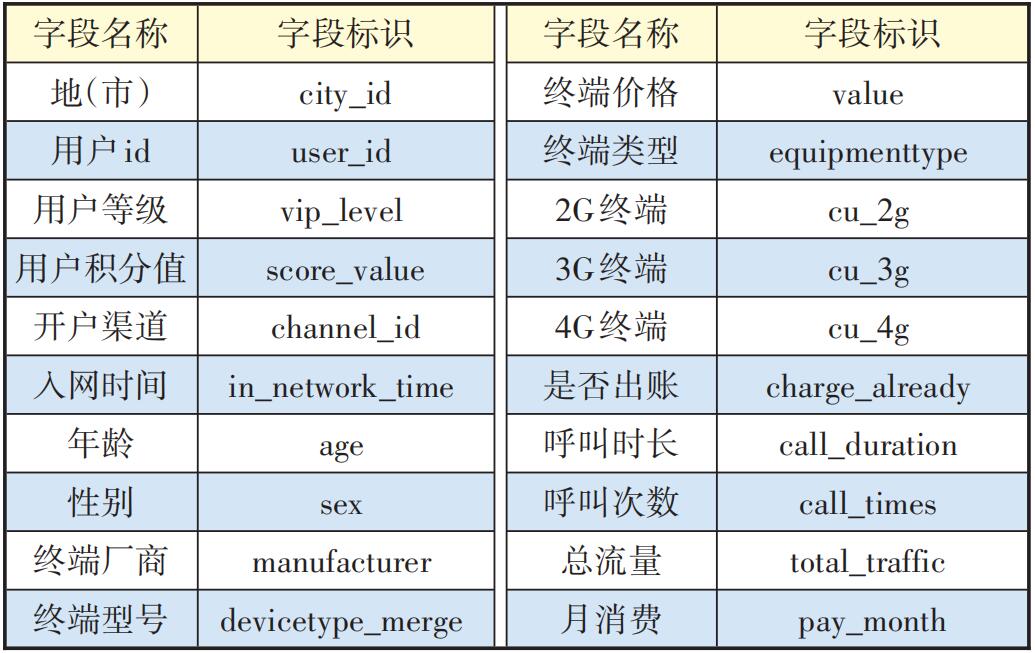
电信企业可利用的输入数据包括但不限于:用户的基本信息、用户的账单信息、用户的详单信息、用户的终端信息、用户缴费情况等各种表结构信息。本次试验采用了电信企业的用户账单信息、用户详单信息和终端库信息3张表中的字段,通过用户编号user_id的关联,汇聚成一张数据宽表,其中账单和详单信息使用至少3个月以上的信息(见表1)。
表1 数据宽表
为了增加模型的有效性,可以通过单个算法的测试以及融合多个算法的测试,例如可以在实践应用时,第1次采用逻辑回归算法建模和预测,第2次采用决策树算法,第3次采用XGBoost算法,第4次采用将逻辑回归和XGBoost算法的结果合并的预测方法。采用XGBoost算法建模的实验伪代码如下。
第1步:
#导入xgboost模块:
import xgboost as xgb
第2步:
#读取训练属性,为建模准备输入数据:用户离网预测是一个典型的有监督分类问题。因此需要读入训练特征,以及目标标识:
feature_file_name = "train.feat"
target_file_name = "train.target"
feature_file = open(feature_file_name,'rt')
target_file = open(target_file_name,'rt')
#准备矩阵型训练数据:
#读写样本特征,生成训练矩阵training_matrix和目标列表target_list。
第3步:
#生成训练模型,在测试集上验证并调参。
param = {'booster':'gbtree','objective':'binary:logistic','eval_metric':'auc','max_depth':5,'min_child_weight':1,'subsample':0.9,'lambda':10,'gamma':0.0,'eta':0.3,'silent':1 }
num_round = 100
dtrain=xgb.DMatrix(training_matrix,label=target_list)
bst = xgb.train(param,dtrain,num_round)
bst.save_model('model.xgb')
第4步:
#使用及应用。将生成的xgb模型用于需要生成标签的样本集。
#加载样本属性数据
#加载训练模型数据
bst = xgb.Booster({'nthread':4})
bst.load_model("model.xgb")
#预测
dtest = xgb.DMatrix(trainingMatrix)
y_pred = bst.predict(dtest)
result_list = (y_pred ≥ 0.5) × 1
#结果写入文件
result_file = open(result_file_name,'wt')
for index in range(len(y_pred)):
result_file.write('%s/t%d/n'%(uid_list[index],result_list[index]))
result_file.close()
第5步:
#如果采用多算法融合,例如除XGBoost之外同时采用逻辑回归的判决概率,可将XGBoost输出判决概率和逻辑回归输出判决概率取均值,作为最终判决依据。
bst = xgb.Booster({'nthread':4})
bst.load_model("model.xgb")
pred_leaves = bst.predict(xgb.DMatrix(test_matrix),pred_leaf=True)
tree_node_enc = OneHotEncoder()
lr_model = LogisticRegression()
……
transformed_feature = tree_node_enc.transform(pred_leaves).toarray()
y_pred = lr_model.predict_proba(transformed_feature)[:,1]
result_list = (y_pred ≥ 0.5) × 1
5 总结
使用机器学习来预测用户离网,是大数据相关技术在电信企业的一个典型应用[8-11]。机器学习在现代的应用已经相当广泛,用户可以不必再开发最原始的算法代码,而是直接安装、调用现成的模块或者API。电信企业的数据资产是宝贵的矿藏,通过数据挖掘,无论是用于提升企业内部运营效率,还是和外部合作进行行业应用支撑,都将是一笔非常可观的财富。
参考文献:
[1] HARRINGTON P.机器学习实战[M].李锐,李鹏,曲亚东,等,译.北京:人民邮电出版社,2013
[2] 王凯. 数据挖掘在移动离网用户分析模型中的研究与应用[D]. 郑州:郑州大学,2014.
[3] 陈康,向勇,喻超.大数据时代机器学习的新趋势[J].电信科学,2012,28(12):88-95.
[4] 周志华,王珏. 机器学习及其应用[M]. 北京:清华大学出版社,2009.
[5] HASSOUNA M,TARHINI A,ELYAS T,et al. Customer Churn in Mobile Markets A Comparison of Techniques[J]. International Business Research,2015,8(6):224-237.
[6] SINGH I,SINGH S. Framework for Targeting High Value Customers and Potential Churn Customers in Telecom using Big Data Analytics[J]. International Journal of Education & Management Engineering,2017,7(1):36-45.
[7] DONG R,SU F,YANG S,et al. Customer Churn Analysis for Telecom Operators Based on SVM[C]// International Conference On Signal And Information Processing,Networking And Computers. Springer,Singapore,2017:327-333.
[8] 张婧姣. 电信社会网络离网用户预测及分析[D]. 北京:北京邮电大学,2017.
[9] 陈晔. 基于组合预测的电信客户流失预测分析[D].长沙:湖南大学,2011.
[10] 杨晓峰,严建峰,刘晓升,等.深度随机森林在离网预测中的应用[J].计算机科学,2016,43(6):208-213.
[11] 赵慧,刘颖慧,崔羽飞,等.机器学习在运营商用户流失预警中的运用[J].信息通信技术,2018,12(1):14-21.
来源:邮电设计技术





