

GAN作为一个听名字就让人热血狂燃的生成模型,近年来在CV,NLP,语音处理等各个领域都取得了骄人的成果。本文介绍了GAN的基本思想,损失函数,优化过程,揭开了这个神秘角色的第一层面纱。
2014年,Good Fellow等人将生成对抗网络的概念引入机器学习范畴,开启GANs元年。此后的数年,GANs携带着它形形色色的变种横扫生成模型领域,在每年的AI顶级会议中成为当之无愧的流量鲜肉(相关paper数量增长见图1,且其中70%都是华人发表),并被Yann Lecun盛赞为“十年来机器学习领域最有趣的想法”。那么,这个中文译名让人瞬间想撸起袖子的大魔王,GAN,到底有什么本事能在深度学习进入相对瓶颈的阶段,还能强势占据一席之地,和变分自编码模型VAE二分天下的呢(这个‘天下’有点小,是深度学习生成模型的天下)。如果你愿意随本文一起一层一层剥开它的心,你会发现你会讶异,原来传说中的GANs并没有那么深不可测,核心原理比鸡兔同笼还浅显(因为笔者已经记不清鸡兔同笼的解法了)。好,我们开始剥史上最智能的“洋葱”!
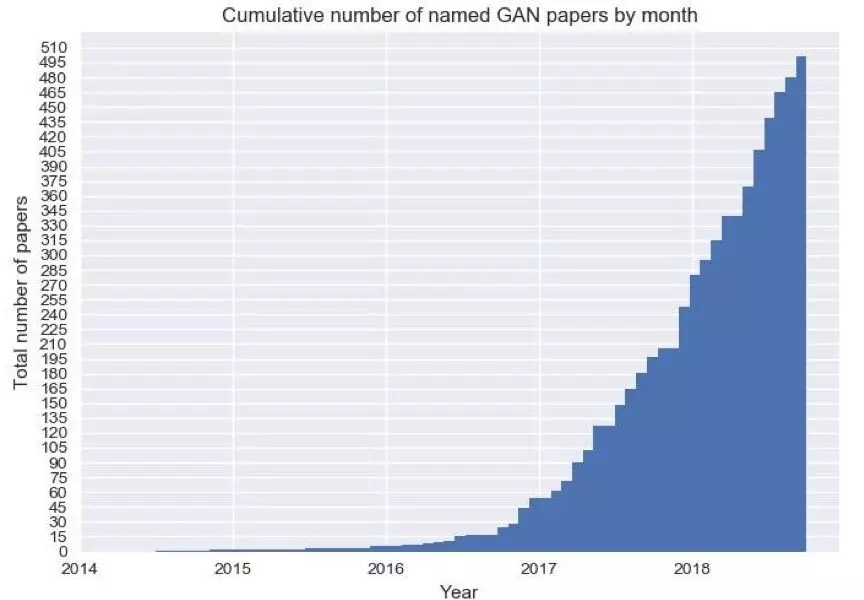
图1
监督学习二人转:生成模型和判别模型
首先,嗯,剥开洋葱第一层:什么是监督学习?监督学习就是有‘老师’带领的学习,学习目的很明确,无监督学习就是没有‘老师’带领的学习,学到什么算什么,这里的‘老师’指的就是学习数据的‘标签’(注意,这只是一个形象而不精准的说法,后续的文章会专门针对监督学习和无监督学习进行标准阐述,敬请期待)。
然后我们来了解监督学习的一个重要的概念:生成模型和判别模型的区别。注意,这层洋葱皮可能会让部分同学眼部不适,随后会给出眼药水进行治愈。我们快速手起刀落,切开洋葱,眼睛流泪的同学可以快速跳至解药部分。首先假定我们已知数据X={x1,x2,x3,…,xn},这些数据可能是图像、声音、或已经预提取的特征向量,数据对应的标签Y={y1,y2,y3,…,yn},我们需要解决的问题是建立X与Y之间的概率映射关系。
* λ生成模型
生成模型并不直接针对条件概率分布P(Y|X)建模,而是将联合概率分布P(X,Y)作为学习目标,进一步,条件概率可以基于联合概率,通过概率公式来进行转化计算,如下所示:
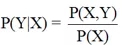
公式1
即
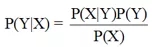
公式2
所以生成模型关注的是先计算出联合概率分布,再计算条件概率分布。
* λ判别模型
判别模型相对简单,直接将条件概率分布P(Y|X)作为学习目标,即对于给定的数据x,判别模型预测x属于每种标签y的概率。与生成模型的一个明显区别已经呼之欲出,即判别模型不关心数据集X服从什么样的实际概率分布,而是直接根据条件概率来学习决策函数Y=f(X)。
已然忘却了概率论基础概念的同学可能被第一层洋葱辣得眼泪横飞,眼药水在此:
生成模型属于统计学习范畴,从大量的数据中寻找真实分布规律;而判别模型只关心不同类型的数据的差别,利用差别来进行分类。
我们常见的机器学习的各种算法都可以按照该定义进行分类:
生成模型-朴素贝叶斯、隐马尔可夫(em算法)
判别模型- k近邻法、感知机、决策树、逻辑回归、线性回归、最大熵模型、支持向量机(SVM)、提升方法、条件随机场(CRF)
GANs之父的灵光一闪
长期以来,生成模型与判别模型各司其职,左右护法,在不同的领域各自精彩纷呈地高歌猛进。2014年,这两兄弟开始了开启时代的协作,Good Fellow将博弈论和对抗思想引入,让生成器和判别器左右互搏,各自对抗进化,以此来生成更逼真的数据。
现在我们开始剥第二层洋葱。GANs,全称为Generative Adversarial Nets(生成对抗网络),它包括了生成器(简称G)及判别器(简称D)两个重要部分。
生成器G:
输入为给定的随机噪声向量noise,输出目标是生成符合真实数据分布的样本,如图片、音频、特征数据等等。
判别器 D:
目标为判定输入数据的真伪,本质上是一个二值分类器,当输入为真实数据时,输出为1,输入为由 G 生成的假数据时,输出为0。
当训练过程开始以后,整个模型的优化过程是一个“二元极小极大博弈(minimax two-player game)”的问题。G作为‘造假者’,会穷尽所能去学习真实数据的分布,并伪造出fake的数据,希望能骗过D。博弈的另一端,D则希望不断去学习真实数据和伪造数据的差异性,并以此提升自己的鉴别能力。理论上来说,博弈的最终结果会达到一种纳什均衡,促使‘造假者’G生成逼真的假数据。
眼药水又来了,把D想象成咱们的执法打假部门,G就是莆田的非著名造鞋厂商,一开始不管是打假部门还是莆田造鞋厂自身能力都不足,一个分辨真伪球鞋的把握不大,一个也只具备极其稚嫩的仿冒技术。随后,我们不断给厂商展示阿迪|耐克|靠背|新平衡|乔丹的最新款式,让厂商工人不断优化自己的仿冒技术,打假部门自然就压力巨大。为了缓解压力,执法部门连夜开会,不断研究原版鞋与made in 莆田的区别,天亮后已经具备将当前造假厂商一锅端的能力。厂商们不甘束手就擒,继续研究新款式正版鞋制作工艺…… 如此循环往复,执法部门D的鉴假能力提升也迫使造假者G生产出更逼真的伪造鞋,最终莆田造学得了真鞋的精髓,泛滥成灾。
我们以原论文中的一幅图为例来讲解一下GANs伪造数据的能力是如何修炼出来的。
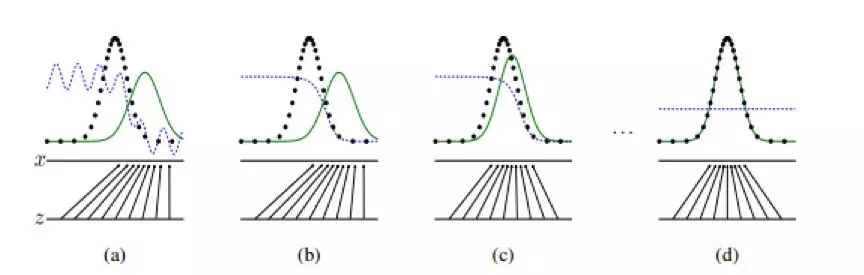
图2
图2中用蓝色的虚线来表示D的判别能力,真实的数据样本生成分布用黑色的虚线来表示,由G伪造的数据分布用绿色实线来表示。图中下部则展示了从噪音采样z经过生成器G后映射到输出x的关系变化过程。
GANs的目标是让生成器使用伪造的样本分布(绿色实线)去模拟真实的样本分布(黑色虚线),使两条线尽量一致。
(1)在初始状态(a),生成器产生的数据和真实数据分布相差非常大,同时,判别器也不能太稳定工作对二者加以区分;
(2)在(b)中,首先我们锁住生成器G,通过训练判别器D,使判别器能识别出未经训练的生成器生成的伪造数据和真实数据的区别;
(3)在(c)中,我们训练生成器G,让其具备欺骗当前判别器的能力,生成的数据相比之前更逼近真实样本分布;
(4)重复上述(2)(3)步,迭代n次后,从理论上我们可以达到(d)图的状态,即生成的样本分布能基本拟合真实的样本数据分布,同时判别器对任意数据的判定概率均为0.5,即无法区分出是否是真实数据还是伪造数据。 与其说生成对抗网络定义了一种网络,不如说定义了一种框架及思想。其中的G和D可以是卷积网络CNN,可以是老牌生成器VAE,可以是时间序列相关模型RNN,也可以是莆田造鞋怪,这就使得不挑食的GANs的应用相当广泛,在图像,语音,文字等领域均有用武之地。
博弈游戏公式-loss损失函数
模型优化当然需要定义损失函数,流量明星GANs也不例外。首先我们聚焦判别器D,本质上它是一个分类器,对于分类器,我们很自然地可以联想到常见的交叉熵损失函数。
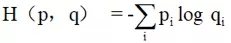
公式3
其中Pi为真实的样本分布,qi为G伪造的样本分布。
同时,由于D实质上只输出{0,1}二分类,所以针对单个样本,可以强行将函数展开成两项:
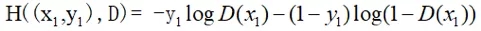
公式4
基于此,对于N个样本,损失函数为:
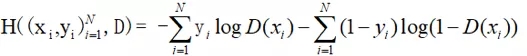
公式5
上式中的待鉴定数据Xi 在GANs模型中有两个来源,一个来自真实的数据分布,我们记为,另一个来源是输入一个噪声z(z一般满足某种已知常见分布,如正态分布),从生成器G中伪造出一个X,我们记为G(z),将两个来源替换到上式中,得到GANs判定器损失函数的一般期望表达形式:
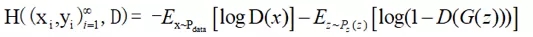
公式6
我们选择了一条最容易理解,最不辣眼睛的方式推导了GANs判定器的损失函数,而通常我们见到的GANs损失函数都是以如下形式呈现的:
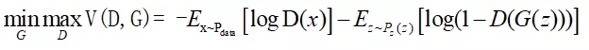
公式7
这种形式的损失函数更能体现对抗的MinMax博弈过程,其中V(D,G)表示真实样本与伪造样本的差异程度,对于生成器G来说,希望尽量缩小这个差异(min),对于判别器D来说希望能尽量拉大这个差异(max),一强一弱,此消彼长地对模型进行迭代优化。
总结
本文旨在将GANs的基础概念和思想呈现在读者眼前,从纯理论方面验证了GANs的超强拟合能力,对于GANs本身的学习和研究来说可谓是冰山一角,沧海一粟。GANs的天赋异能让它在特定领域如鱼得水,但自身的弱点缺陷也是触目惊心,本文尚未涉及到更深层次的探讨,精彩未完,敬请期待。
最后,附送一个冷知识,为什么我们通常在paper和文章中既能看到GANs,也能看到GAN,哪种写法是对的?其实都对。GANs中的s指的是Nets,也就是把生成对抗网络看做多个(至少有生成器和判别器两个)模型,而写作GAN的,是把整个生成对抗网络视为一个模型了。 
作者:青榴实验室 来源:移动labs





