

(魏德龄/文)当人们已经习惯了在线视频会议,对于这种沟通方式在使用过程中的痛点也被放大,解决问题提升体验成为了目前业界对于视频会议功能的新发力点。对于当下视频会议过程中,因信号问题造成人物图像不清晰、成像角度不佳、由于客观原因个人形象不佳的问题,英伟达在CVPR 2021上最新展示的Vid2Vid Cameo成功通过AI解决了这一问题。
只需两个元素告别尴尬
根据英伟达媒体会上的演示来看,只需要录入两个元素,就能通过AI来解决上述视频会议过程中的尴尬问题,两个元素分别为一张人物外貌照片和一段视频流。之后Vid2Vid Cameo就能在视频通话的过程中模拟出真实高清的人物形象,或是虚拟的卡通形象,这些形象还可以根据会议人的面部形态进行匹配。
这就意味着,如果会议人员没有着正装,Vid2Vid Cameo也可以根据已经录入的元素来模拟出与会者的正装形象,并且可以进行动态显示。而如果与会者没有化妆,或个人形象暂时不佳,Vid2Vid Cameo也能以此前元素中的理想形象,来动态的呈现在会议的视频中。
这项功能同样可以应用于目前很多厂商在关注的通过卡通虚拟形象来进行在线交流的功能中,Vid2Vid Cameo同样可以虚拟出一个卡通形象,用户只需上传一张卡通头像便可实现,通过追踪与会者的五官变化,来进行实时的虚拟形象显示。
Vid2Vid Cameo甚至还能可以实现移花接木,通过AI将某个人的动作转移到另一个人的参照图像上,同样可以生成更逼真、更清晰的结果,优于先进的模型。

值得一提的是,Vid2Vid Cameo还能大大降低网络压力,让以往视频会议过程中由于网络问题所造成画面卡顿及马赛克现象一去不复返。原因在于在实际虚拟过程中通过仅来回压缩及发送头部位置和关键点,而不是完整的视频流,此技术将视频会议所需的带宽降低 10 倍,从而提供更流畅的用户体验。
AI助力全新视频会议体验
本次展示的Vid2Vid Cameo 是用于视频会议的 NVIDIA Maxine SDK 背后的深度学习模型之一,它借助生成式对抗网络 (GAN),实现了仅用一张人物2D图像即可合成逼真的人脸说话视频。Vid2Vid Cameo是英伟达在CVPR 2021上发表的28篇论文之一。
实现上述功能的过程中,AI发挥了重要作用,AI可以将用户的面部动作映射到参考照片上,当侦测到与会者身体运动后,也能自动调整角度,让与会者看上去可以一直处在面向摄像头的状态。
这一模型基于 NVIDIA DGX 系统开发,使用包含 18 万个高质量人脸说话视频的数据集进行训练。网络已掌握识别 20 个关键点,这些关键点可用于在没有人工标注的情况下对面部动作进行建模。包括眼睛、嘴和鼻子在内的点对特征的位置进行编码。
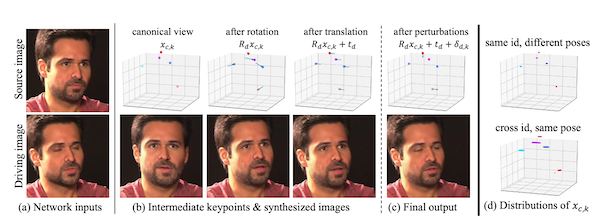
在传输过程中,视频会议平台只需传送关键点信息接口,视频接收端会使用此信息来模拟参照图像的外观以合成一个视频。另外,该模型还可以进行调整,传输不同数量的关键点,以实现在不影响视觉质量的条件下,适应不同的带宽环境。这也就是上文提到的可以大幅节省传输流量的原因所在。
目前,这一能够让视频会议人员告别个人形象尴尬的功能即将登陆 NVIDIA Maxine SDK,为开发者提供经过优化的预训练模型,以便在视频会议和直播中实现视频、音频和增强现实效果。开发者已经能采用 Maxine AI 效果,包括智能除噪、视频升采样和人体姿态估计。SDK 支持免费下载,还可与 NVIDIA Jarvis 平台搭配用于对话式 AI 应用,包括转录和翻译。
也许在不久以后,无论是刚刚起床,还是身在海滩边度假的你,当临时视频会议接入的时候,都能西装笔挺、头发一丝不乱的出现在会议之中,随时以最好的形象进行沟通。





