

近日,中国移动研究院联合知存科技完成基于NOR-Flash存算一体芯片的视频超分技术验证,为存算一体芯片在算力机顶盒、AR/VR终端、边缘视频解码器等场景支撑高效视觉AI应用奠定基础。视频超分技术是近年来愈发受到学术界和产业界关注的一种图像处理技术,旨在将低分辨率的视频或图像转化为高分辨率图像,以提高图像的质量。视频超分技术在许多领域有广泛应用,如电视和电影产业、监控系统、医学图像处理等。目前视频超分技术主要采用深度学习方法实现,通过在大量高分辨率和低分辨率图像对上进行训练,学习到图像的映射关系,从而能够更准确地重建细节丰富的高分辨率图像。视频超分算法模型计算并行度高,数据搬运频繁,计算设备的运行伴随着大量能耗,给视频超分应用(尤其是端侧)带来巨大挑战。
存算一体架构将数据存储单元和计算单元融合为一体,能显著减少数据搬运,极大地提高计算并行度和能效。本次试验采用知存科技的40nm制程WTM2101存算一体芯片作为计算载体(图1),该芯片于2022年3月在业内率先实现商用量产,采用NOR-Flash非易失存储器件实现AI权重存储和矩阵乘加运算,支持卷积、全连接、Relu等深度神经网络算子,可以为端侧AI计算提供高能效的算力。

面向WTM2101存算一体芯片计算特性,项目团队通过算子优化技术,将超分模型中的AI算子转换为存算一体芯片支持的算子类型,更好地发挥存内计算优势。针对阵列规模有限的问题,基于结构重参数化思想,将带有局部特征提取算子的多分支卷积结构融合转换为一个3×3卷积层(图2-a),实现近5倍的参数量压缩,得到轻量化超分模型骨干网络(图2-b)。在此基础上,利用权重量化技术,将 FP32权重转换成INT8整数,实现超分模型在存算一体芯片的适配和高效运行,计算能效相比基于传统冯·诺依曼计算架构的12nm制程GPU提升2倍以上。
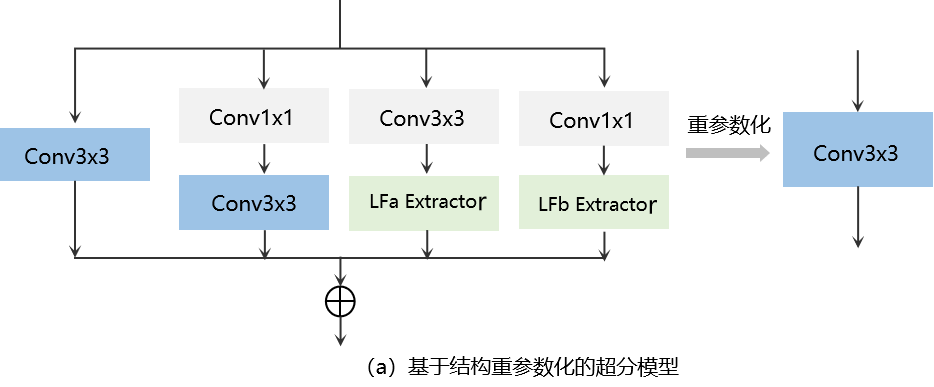

图2 面向存算一体芯片的超分模型结构
为了支持视频超分模型在WTM2101芯片的编译、部署和推理,项目团队研发面向存算一体芯片的软件计算引擎(图3),兼容Pytorch、Tensorflow等多种AI框架,提供AI模型编排、部署、推理、管理、验证、优化等全流程服务,有效降低用户的开发门槛,提升开发调试效率。另外,软件计算引擎提供了一系列的模型误差补偿技术,有效解决了存算一体芯片模拟计算存在误差、器件非理性特性等问题,实测显示视频超分模型在存算一体芯片上计算的特征图(feature map)和CPU上计算的特征图余弦相似度为91.8%,在提升计算能效的同时确保了足够高的计算精度。图4为基于存算一体芯片的4倍图像超分效果。

图3 存算一体软件计算引擎

下一步,中国移动研究院将不断深耕存算一体领域,一方面发挥应用牵引作用,推动存算一体芯片在算力机顶盒、AR/VR终端等场景落地应用;另一方面持续完善软件计算引擎功能,助力存算一体软件生态构建。





