

近日,中国移动研究院撰写的论文“Collaborative Training for Compensation of Inference Errors in NOR Flash Computing in memory Chips”被第二十七届IEEE国际计算机协同计算与设计大会(CSCWD 2024)录用,中国移动研究院专家受邀出席大会并就论文方案做演讲。
近年来人工智能尤其是大模型对算力的需求呈爆炸式增长,而经典的冯·诺依曼架构因存储与计算分离带来的数据搬运时延及能耗成为算力增长的主要瓶颈。存算一体技术在存储原位实现计算功能,可以突破冯·诺依曼架构瓶颈,大幅提升算力和能效水平。但由于存算一体器件存在非理想特性,造成数据转换误差和数据写入误差问题,从而影响计算精度。针对上述问题,论文提出一种面向存算一体芯片的AI模型协同训练架构,通过在模型训练过程中使用存算一体芯片的推理结果进行反向传播并更新模型权重,从而提升模型在存算一体芯片推理的鲁棒性。该成果为面向存算一体芯片的模型训练提供重要参考,对于推进存算一体芯片的工程化和产业化有重要意义。
在训练架构方面,论文提出了一种面向存算一体芯片的新型协同训练架构(图1),包括数据集量化、模型训练与量化、模型片上计算三部分。首先按照芯片计算精度对输入的训练数据集进行INT8量化,然后基于量化数据集在CPU/GPU上训练出FP32精度的模型,再将模型进行量化后部署到存算一体芯片上并基于量化数据集进行前向计算,最后基于芯片实际计算结果与真值计算模型损失并反向传播更新模型权重,依此训练出来的模型可以极大提升在存算一体芯片上推理计算的鲁棒性。
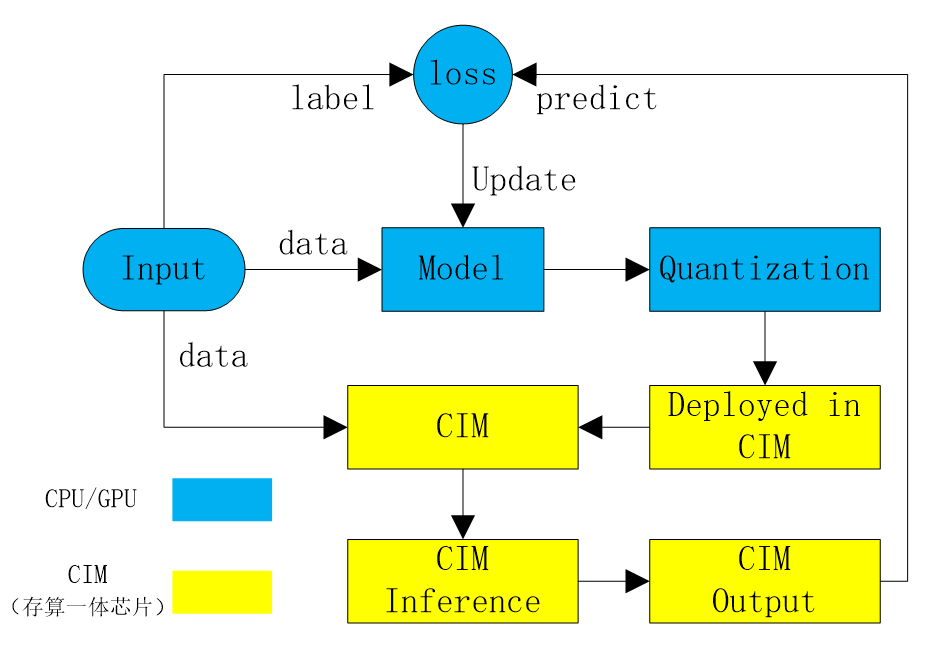
图1 面向存算一体芯片的AI模型协同训练架构
此外,论文提出了一种基于对称定比例因子的协同量化方法,可以将芯片端的INT8计算精度和训练环境的FP32精度模型有效融合(图2)。针对芯片数据[-128, 127]的精度范围,在模型训练更新权重时将权重区间限制在[-0.125, 0.125]范围,从而保持统一的1024权重比例因子,避免在训练过程中因更新量化因子而引入新误差,并提升模型训练收敛速度。
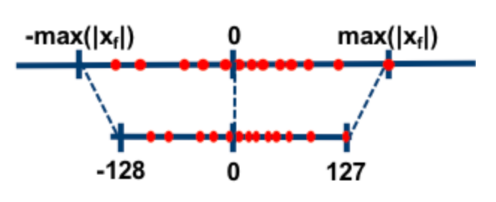
图2对称定比例因子量化方法
下一步,中国移动研究院将持续开展存算一体芯片、软件、算法、应用等相关技术研究,推进存算一体在端、边、云等应用场景的广泛应用落地。





